
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 통계실험
- 머신러닝
- gam모델
- 통계대학원
- 통계디자인
- 데이터사이언스
- 영국통계대학원
- 관찰연구
- 통계예상문제
- Titanic - Machine Learning from Disaster
- Smoothing
- 타이타닉데이터
- literature review
- 통계학석사
- RCB
- cohort study
- Spatial Data
- soap film smoothing
- 케글타이타닉
- 영국대학원
- 통계석사
- statistical experiment
- 영국석사
- blocking
- Machine Learning
- 논문제안서
- Data Science
- 코호트연구
- mean model
- factorial design
- Today
- Total
DS and stats
[Machine Learning] Brute force 본문
첫 머신러닝 과제였던 brute force 실습.

우선, 컴퓨터 사이언스에서 brute force란, 가장 일반적인 문제풀이 방법이면서,
시스템적으로 정답이 될 수 있는 모든 가능한 후보군을 나열하여
그 각각의 후보군이 정답이 되는지 일일이 하나하나 확인하는 건데
쉽게 설명하자면,
그냥 줄 세워놓고 너는 해당되냐, 안 되냐!! 이렇게 확인한다고 생각하면 좀 더 쉬울 것 같다.
어쨌든 머신러닝은 별 관심도 없고
처음 배우는 나로서는 생소했던 개념!!
유명한 데이터셋인가.. 잘 모르겠 ㅋㅋㅋ
r, g, b를 이용해서 0이면 background, 1이면 skin인데
모델을 학습시켜서 input을 넣었을 때 이게 background인지, skin인지 알아야 한다.

총 데이터 수는 245,057
그중 background는 194,198
skin은 50, 859
우선 학습시키기 위해서는 학습 데이터와 테스트 데이터를 나눠야 한다.

이미 주어진 부분이라 자세히 보지는 않았는데
Train : Test 데이터의 비율을
보통은 70:30으로 나눈다고 알고 있었는데 여기는 50:50으로 임의로 나눴다고 적혀있다

간단히 평균과 표준편차를 알아보니까
숫자의 분포가 다른 것을 알 수 있다.
이걸 이용해서 간단하게 mean +- std를 해서 범위를 지정해보았다.

대강 70-85%의 비율이 나오면 괜찮게 범위 설정을 했다고 하는 편.
결과는 나쁘지 않았는데
머신러닝을 공부하고 있으니까
멍청한 컴퓨터를 공부시켜서 이 친구가 90% 이상으로 background와 skin을 구분하게 해 보자
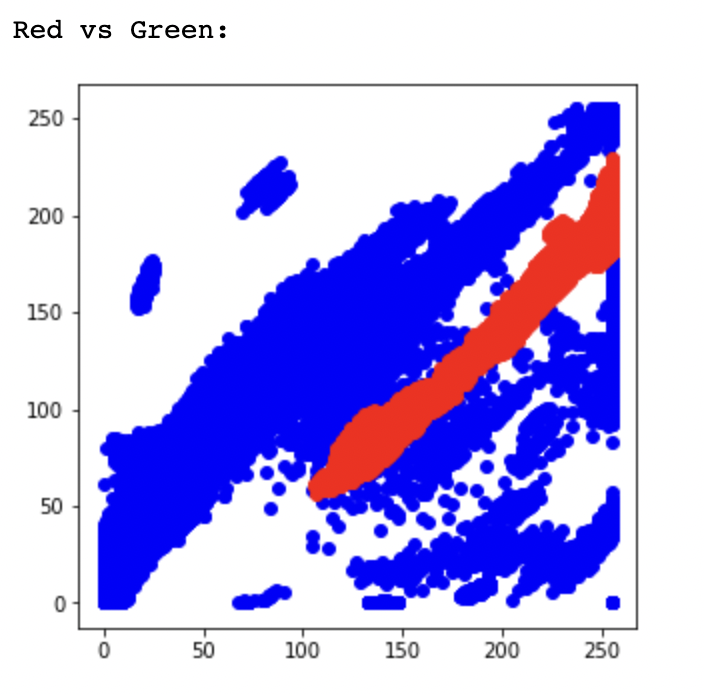

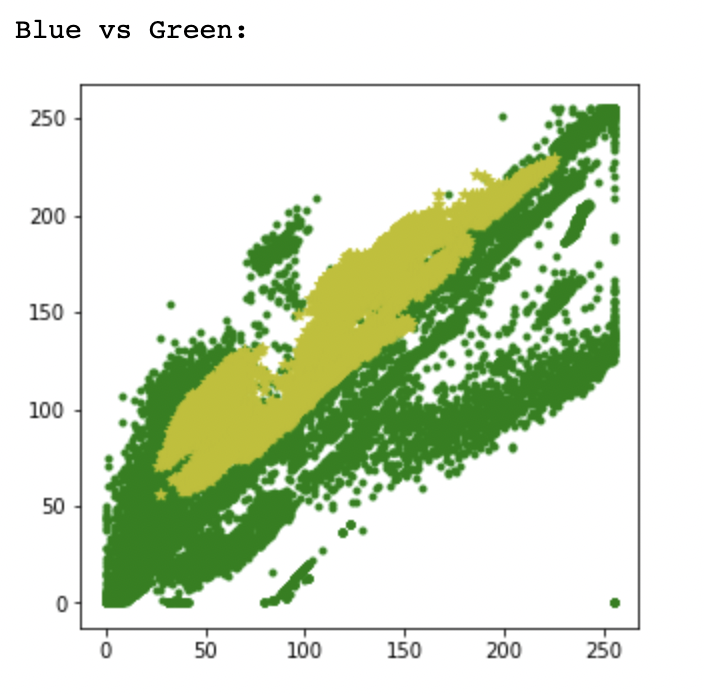
이 세 가지 그래프를 비교했을 때
가장 선형적인 모형을 보이는 Red vs. Green 그림을 선택하고
선형 방정식을 만든다.
(100,50), (200, 150) 정도로 두 점을 선택하고
이때 정확하게 점의 좌표를 구할 필요는 없다. (구할 수도 없고..)
red = green -50 으로 대강 구할 수 있는데
다시 쓰면, green - red - 50 = 0 으로 나타낼 수 있고,
이전에 구했던 간단한 통계식을 이용하여 대입해주면 새로운 관계식을 얻을 수 있다.
물론 brute force이기 때문에
찍어 맞춰서 방정식이 나오는 경우도 있..
나도 처음에 할 때 한 친구는 이것저것 하다 보면 나오니까 닥치는 대로 해보라고 했고,
그 이후에 다른 친구가 공식을 알려줬다.

최적화를 통해 변수를 다 때려 박고 그중에 제일 정확한 결과를 얻게 된다.
아무래도 시간은 오래 걸리는 편인 것 같다.
보통 20분은 잡아야 하는 듯..
최적화 전
1) 닥치는 대로 해 본 경우


2) 공식을 사용한 경우


최적화 후

최적화를 통해 95%를 얻었는데 공식이랑 비슷한 것을 볼 수 있다.

'Data science - sem 1' 카테고리의 다른 글
| [Machine Learning] 개요 (0) | 2021.12.24 |
|---|---|
| [stfds] Noughts and crosses (Tic-tac-toe/빙고) (0) | 2021.12.22 |

