
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- gam모델
- 통계디자인
- Data Science
- 통계석사
- 통계실험
- 타이타닉데이터
- 케글타이타닉
- Smoothing
- 논문제안서
- Machine Learning
- literature review
- 통계예상문제
- soap film smoothing
- factorial design
- Titanic - Machine Learning from Disaster
- 머신러닝
- 영국석사
- mean model
- 영국통계대학원
- 데이터사이언스
- 통계학석사
- blocking
- 관찰연구
- 통계대학원
- Spatial Data
- cohort study
- 코호트연구
- statistical experiment
- RCB
- 영국대학원
- Today
- Total
DS and stats
통계 실험 디자인하기 - CRD(Completely Randomised design) 본문
통계 실험 디자인하기 - CRD(Completely Randomised design)
으르미 2022. 3. 11. 07:53Statistics: the science of collecting, analysing, and drawing conclusions from data.
데이터 수집하는 방법:
1. Sampling surveys: 공적 조사 없이 유한한 모집단의 특징을 추정하는것이 목적
2. Observation studies and Experiments: 모집단에서 두 개 이상의 측정된 변수간의 관계를 결정
eg. 흡연과 폐암발생 간의 관계(흡연, 폐암 발생횟수는 이미 측정된 변수이고 우리가 할 일은 관계를 결정하는 것
우리는 2에 초점을 맞춰서
Observation studies 와 Experiments의 차이를 알아보자.
Observation studies: 자연적인 환경에서 관찰된 데이터이고, 그래서 원인과 효과를 찾기가 어렵다. 과거에 서로 영향이 있던 변수들의 관계를 가정할 때, 그 변수들이 미래에도 존재해야 한다.(하지만, 자연적인 상황에서는 확신할 수 없음.)
Experiments는 제한된 환경에서 관찰된 데이터이다. 특정 상수나 factors를 고정하고 의도적으로 다른 변수가 변화를 관찰하는 것.
그래서!! 우리는 experiment를 디자인해야하는데,
1. 가능한 natural variations는 제거한다
2. 제거하지 않은 natural variations이 테스트 중에 혼란을 주거나 편향시키는 것을 방지한다
3. 최소한의 실험으로 원인과 효과를 규명한다
CRD(Completely Randomised design) with one treatment factor
실험 고안시, 고려해야 할 사항
- experimental unit 이란? 어떤 것이 변화하는 연구의 아이템.
- replicate의 개수는 어떻게 결정할 것인가?
- replicate란, 요인이나 독립변수의 같은 설정으로 실행되는 두개 이상의 실험에서 운영되지만 다른 experimental units을 가지고 있다. Replicate에 따라 lurking 변수와 상속변수가 다를 수 있기 때문에 반응변수도 다를 수 있다.
- random이란?
- 독립변수란? (treatment factor)
- dependent(response) 변수란?
- 실험에 의해서 어떤 것이 통제되는가?
- lurking 변수란?(편향을 유발시키는 변수)
- 그래프에 의해서 어떻게 결론낼 수 있는가?
=> 한 독립변수(treatment variable)은 t 레벨을 가지고 있다.
총 n개의 experimental units은 t개의 그룹으로 무작위하게 나누어지고, 각 그룹은 treatment factor의 레벨 중 하나를 가진다.
즉, n = t*r인데 여기서 r은 replicates (balanced design)
각 r이 다른 값을 가질 수 있는데 이 때는 unbalanced design이 된다. 이 경우는 복잡하므로 우선 제외한다.
반응변수는 모든 experimental units에서 관찰된다. (예를 들면, 정의에 따라 어떤 시점이 될 수도 있다.)
다른 독립변수들은 고정해놔서 결과에 편항되지 않도록 해야한다.
이 디자인은 모든 experimental units가 비슷한 성질을 가지고 있어야하고 오직 하나의 factor만 있을 때 사용되어진다.
다시, replication이 필요한 이유
하나의 예시로 t번 시험하는 것보단 r개의 다른 종류로 t번 실험하는게 더 나은 결과를 얻을 수 있다!
treatment factor의 다른 레벨에 있는 replicates로 우리는 실험적 오류(experimental error)의 분산을 추정할 수 있다.
*experimental error: 특정 실험간의 반응변수와 독립변수나 factors의 동일한 설정에서 행한 모든 실험의 평균의 차이. 크게 bias error와 random error로 구별할 수 있다. bias error는 실험동안 일정한 숫자나 일관된 패턴으로 변경되는 경향이 있고, random error은 예측하지 못한 방식에서 하나의 실험에서 다른 실험의 변화하고 평균은 0이 된다.
replication없이, treatment 차이가 실제인지, 아니면 실험에서 특정 experimental units의 무작위 표현?인지 구분할 수 없다.
우리는 최적의 r을 찾아야 한다!
Randomisation
- experimental units에서 그룹으로 무작위하게 나눈 것을 randomisation이라고 함. lurking 변수에 의해서 편향이 발생되는 것을 방지하고자 이 과정을 거치게 된다.
- Experimental units이 무작위화를 거쳤을 때, treatment effect가 0이 된다는 가설검정을 할 수 있다.
정리
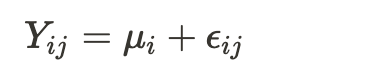
- Y는 반응변수, 확률변수
- mu: mean response(평균반응?), 즉, treatment factor의 i번째 레벨의 모든 가능한 실험의 평균.
- epsilon: 실험오류, 확률변수이기도 함.
'Data science - sem 2 > Statistical design of investigation' 카테고리의 다른 글
| Observational studies and Causal inference (관찰 연구 및 인과추론) (0) | 2022.04.17 |
|---|---|
| [Statistical design] Factorial designs in blocks(RCB) & GCB (0) | 2022.03.15 |
| Statistical design - Anova Table (0) | 2022.03.15 |
| Experimental designs with multiple factors (0) | 2022.03.13 |
| statistical design - Mean model vs. Treatment effects model (0) | 2022.03.12 |



